Do požadavků na znalosti potřebné pro úspěšné složení zkoušky OCUP 2 Advanced (Beta) byla přidána oblast metamodelování rozdělená do tří částí: MOF, fUML a Alf. Níže bez jakékoliv záruky na správnost, úplnost či srozumitelnost poskytuji své poznámky, které si ke zkoušce připravuji. Tato syrová podoba je čistě z toho důvodu, že zkoušky již probíhají a poslední možný termín je 11. srpna. Tak ať u vy z toho něco málo máte.
Poznámky jsem postupně rozšiřoval, viz verze níže. Dále se k němu již zřejmě nebudu vracet.
- 20. 7. 2017 – Verze 1
- 21. 7. 2017 – Verze 2 (přidán popis na základě kapitol 6.2 a 6.3.1 z UML standardu, níže v první části v podkapitolách UML a Model).
- 27. 7. 2017 – Verze 3 (doplněny poznámky ke kapitolám fUML 6.2 a 6.3, obecné povídání o spustitelném UML a jazyku akcí, kapitoly fUML Overview, definice pojmů, abstraktní syntaxi a overview of execution model)
- 28. 7. 2017 – Verze 4 (doplěna kapitola Behavioral Semantics v části fUML a dále Alf – vše). Tímto je vše, co jsem chtěl, doplněno.
The MOF and Metamodeling (12 %)
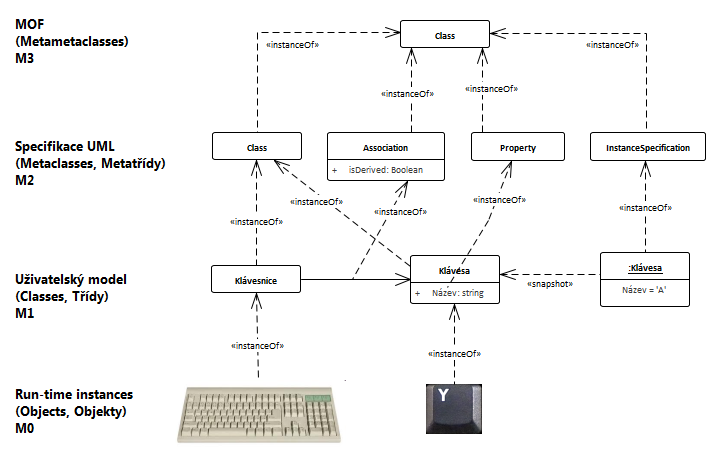
Zkoušené oblasti:
- Architectural alignment
- Models and what they model
- The semantics of languages, models, and metamodels
- The MOF
Zdroje:
- [UML] UML 2.5:
- 6.2 Architectural alignment: All
- 6.3.1 Models and What They Model: All except Execution Scope, which was covered in the main exam
- [fUML] fUML:
- 6.2 On the Semantics of Languages and Models: All
- 6.3 On the Semantics of Metamodels: All
- [WPMOF] OMG White Paper
- Meta-Modeling and the OMG Meta Object Facility (MOF): All
- [MOF] MOF 2.5.1
- 9.1, 9.2 Reflection: All
- 10.1, 10.2 Identifiers: All
- 11.1, 11.2 Extension: All
Moje poznámky:
- Celá tahle taškařice je pro potřeby OMG podporovat jejich MDA (Model Driven Architecture) koncept. Ten je založen na OOP (objektově orientovaném přístupu). [MOF, 1]
- MOF = Meta Object Facility, původně založené kvůli CORBA.
- MOF je dělen na EMOF (Essential MOF) a CMOF (Complete MOF). Jsou to vlastně dva balíčky, přičemž mj. CMOF includuje EMOF.
- EMOF je pro základní schopnost navrhovat objektově orientovaný programovací jazyk a mapování na XMI nebo JMI (Java Metadata Interface) s možností jednoduché rozšiřitelnosti (pomocí tagů, viz dále).
- CMOF pak poskytuje komplet schopnost tvorby meta[*]modelů. [MOF, 6.2] Je založen na EMOF a vybraných elementech z UML. [WPMOF] Daný balík pak nedefinuje žádný nový element. [WPMOF]
- MOF je založen na zjednodušeném UML [MOF 1]. MOF sdílí svůj metamodel s UML [MOF, 6.2]. Uf, tak jak si to vysvětlit tak nějak lidsky?
- Specifikace od OMG sice pracují se 4 měrami abstrakce, ale MOF na to není omezen, těch měr může být libovolné množství.
- MOF slouží pro metametamodelování (model UML je metamodel, uživatelský model je model)
- Reflexe (MOF 9):
- obdoba toho, co znám z .NETu (C#).
- Metaobjekty umožňují používat objekty bez jejich předchozích znalostí (resp. jejich struktury).
- Každý element má přiřazenou třídu, která popisuje jeho vlastnosti a operace. Element je pak instance této třídy. Některé vlastnosti Elementu:
- metaclass: UML::Class
- isInstanceOfType (type: Class, includes Subtypes: Boolean): Boolean
- Identifiers (MOF, 10):
- Element má identifikaci v rámci kontextu, která jej nezaměnitelně určuje/rozlišuje od jiného elementu.
- Používá se např. pro (de)serializaci.
- Identity lze porovnávat (např. pro potřeby rekonciliace apod.)
- Extent (česky asi prostor, rozsah platnosti) je kontext ve kterém se elementy od sebe dají identifikací rozlišit.
- Element může být v libovolném množství extentů (0..*)
- Extent není element, jde o součást MOF schopností.
- Extension (rozšiřitelnost) (MOF 11):
- Možnost přidávat metatřídám tagy (známé z Profilů)
- Tag je třída s atributy name a value (obojí string)
- Tag nemusí být přiřazen žádnému prvku, ale také libovolnému množství (0..*).
- Element nemůže mít přiřazen více než jeden tag téhož jména.
- Tag může být vlastněn jiným elementem.
- Další Z3P (Zkratka ze 3 Písmen), které je vhodné znát [WPMOF]:
- XMI – XML Metadata Interchange – formát dat pro výměnu modelů založených na MOF
- OCL – Object Constraint Language – objektový jazyk pro definici omezení
- CWM – Common Warehouse Metamodel – sourozenec UML, jazyk pro definici dat v datovém skladu
- PIM – Platform Independent Model
- PSM – Platform Specific Model
- MDA – Model Driven Architecture – cílem je z modelu generovat zdrojové kódy na základě transformací. Dle mého naprostý nesmysl a pouze hračka pro akademiky. Ovšem přináší důležité věci i pro lidi z praxe a to je právě různý náhled na totéž, viz PIM či PSM.
- MOF je popsán jak textově, tak graficky (využití prvků UML). [WPMOF]
- Primárním cílem MOF je poskytovat „next-generation platform independent metadata framework for OMG“ postavené na předchozí verzi MOF, XMI 2.1, XMI production of XML Schemas a JMI 1.0. (uf, marketingovej žvást).
- Hlavní výhody:
- Jednodušší pravidla pro modelování metadat (stačí znát omezenou podmnožinu UML).
- Různé technologie mapování (XMI, JMI apod.)
- Širší podpora nástrojů pro metamodelování (čistě proto, že nástroje umí UML, takže můžete i metamodelovat, aniž by o tom ten nástroj věděl) – hezké, jak z ničeho vytřískat hodně.
- MOF stále hojně využívá operaci MERGE (která byla při zjednodušení UML z 2.4.1 na 2.5 z popisu jazyka vynecháno, pozor, metatřída v UML PackageMerge samozřejmě zůstala).
UML
- Definice UML je napsaná/specifikovaná pomocí UML modelu nazvaného metamodel UML. Tento metamodel používá konstrukty z vybrané podmnožiny UML – což je vlastně onen MOF. [UML, 6.2]
- Třídy v metamodelu se nazývají metatřídami. [UML, 6.2]
- Pokud tedy vezmeme UML metatřídu Element, pak víme, že jde o abstraktní metatřídu. Z pohledu MOF jde tedy o instanci metatřídy Class, jejíž atribut isAbstract má hodnotu true. Nebo metatřída Comment má atribut body, což z pohledu MOF je je instance metatřídy Property, jejíž název je body. [UML, 6.2]
- Souhrnem je tedy UML definováno samo sebou (podobně jako např. překladač jazyka c může být napsán v týmž jazyce) nebo funkce může být definována sama sebou (rekurzivně, např. faktoriál). [UML, 6.2]
- Výhodou uvedeného je to, že s UML lze manipulovat tak, jak je definováno v MOF a model lze mít v XMI formátu. [UML, 6.2]
Model
- Model je vždy model něčeho. [UML, 6.3.1]
- Modelem říkáme o skutečnosti to, co nás v dané chvíli zajímá, přičemž abstrahujeme od detailů, které sice popsat/modelovat lze, ale není to potřebné. [UML, 6.3.1]
- UML model se skládá ze tří základních částí (ang. individual things, zkráceně i individuals): klasifikátory, události a chování. [UML, 6.3.1]
- Klasifikátory (classifiers): [UML, 6.3.1]
- popisují množinu objektů.
- Objekt je ve vztahu s jinými objekty, je v nějakém stavu a nabývá nějakých hodnot.
- Události (events): [UML, 6.3.1]
- události popisují množinu možných výskytů takových událostí.
- Výskyt (occurence) je něco, co se stane a má nějakou konsekvenci v modelovaném systému.
- Chování: [UML, 6.3.1]
- popisuje množinu možných vykonávání činností (execution).
- vykonávání činnosti je provedení množiny akcí, které mohou generovat odpovědi na výskyty událostí nebo přistupovat k a měnit stav objektů.
- UML model jako takový NEOBSAHUJE objekty, výskyty události, ani provádění chování (pozor na to, že i použití metatřídy InstanceSpecification je jen modelování).[UML, 6.3.1]
- Provádění chování v modelovaném systému může vyústit ve vytváření a rušení objektů.[UML, 6.3.1]
fUML, kapitola 6.2 – obecné povídání o tom, co je to model a formalizace reálného světa. Nic zásadního pro ty, kteří chápou princip modelování a abstrakce.
fUML, kapitola 6.3 – opět, pokračování teorie o metamodelování (proč to sakra není v MOFu?):
- UML je reflexivní jazyk, neboť je definován sám sebou.
- Minimální reflexivnost: metamodel, který se mapuje sám na sebe. Z pohledu UML (2.4.1 a staršího) se jednalo o Infrastrukturu.
Spustitelné UML a jazyk akcí obecně
Executable UML (xUML, xtUML) je jednak způsob vývoje software a jednak vysoce abstraktní programovací jazyk. Poprvé přišel na svět v roce 2002. V té době šlo o UML profil, který kombinoval grafickou notaci podmnožiny UML se sémantikou pro vykonávání kódu.
Model spustitelného UML může být spuštěno, testováno, laděno a lze měřit výkonnost takového běhu. Dále jej lze zkompilovat do méně abstraktního programovacího jazyka (čímž se stává závislý na platformě daného jazyka).
Spustitelné UML je vyšší abstrakce programovacích jazyků třetí generace (např. C#, Java, C++, Pascal).
Jednotlivé akce, které se mají provádět, jsou určeny tzv. jazykem akcí (action language).
Systém je ve spustitelném UML rozdělen do několika oblastí zájmu, tzv. domén. Tyto domény jsou pak reprezentovány následujícími prvky:
- Doménový diagram (poskytuje pohled na modelované domény).
- Diagram tříd
- Stavový diagram
- Akce a operace modelované jazykem akcí
Aby OMG mělo něco svého a standardizovaného, přišla (světe, div se) se svými standardy. Foundation UML (fUML) je v podstatě jedna z možností spustitelného UML. Pro jazyk akcí OMG vymyslelo Alf (Action Language for Foundation UML). V následujících částech si tedy o fUML a Alfu povíme více s ohledem na požadavky zkoušky.
fUML (6 %)
Zkoušené oblasti:
- Scope
- Terms and Definitions
- Overviews of Abstract Syntax and Execution Model
- Behavioral Semantics
Zdroje
- [fUML] fUML
- 1 Scope: All
- 4 Terms and Definitions: All
- 7.1 Abstract Syntax: Overview
- 8.1 Execution Model: Overview, Behavioral Semantics
Scope
Víceméně obecné kecy s odkazem ještě do superstruktury UML 2.2 (sakra, proč? Slyšel někdo v OMG o aktuální verzi UML?). Stručně řečeno se odkazují na to, že aktivity, stavové stroje a interakce mají „pod sebou“ akce. A tyto akce mají pod sebou dvě funkcionality: inter-object behavior base a intra-object behavior base. Inter-object behavior base říká, jak objekty mezi sebou komunikují, intra-object behavior base říká, k jakému chování dochází uvnitř objektu. Akce, které jsou nad nimi, pak slouží k tomuto popisu. Toto povídání je ještě v UML 2.4.1, ale v UML 2.5 již není. Každopádně fUML popisuje právě ony dva prvky: inter-object a intra-object behavior base.
Obecně lze říct, že fUML definuje pro UML virtuální stroj, na kterém může UML běžet.
Osobně se domnívám, že v OMG někomu opravdu řádně hráblo. UML je modelovací jazyk. MODELOVACÍ. Není pro to třeba dělat virtuální mašinu jen proto, že si na tom někdo postavil doktorát. No nic, pojďme dál.
Terms and Definitions
Upozornění: z nedostatku času doporučuji si tuto kapitolu (je čtvrtá) přečíst v fUML standardu v originále. Z nedostatku času nebudu nyní trávit čas nad lepším než podprůměrným překladem. Očekávám, že v testu na to dotazy budou.
Base Semantics – definice sémantiky vykonávání konstruktů UML použitých ve vykonávajícím modelu za použití formalismů jiných, než dává vykonávající model sám o sobě. Jelikož je vykonávající model UML model, základní sémantika je nutná z důvodu dosažení acyklického základu pro vykonávající sémantiku definovanou vykonávajícím modelem. Základní sémantika poskytuje význam pro běh pouze těch konstruktů UML, které jsou obsaženy ve vykonávajícím modelu. Vykonávající model pak definuje význam běhu libovolného UML modelu založeného na základní podmnožině (viz foundational subset). Libovolný nástroj, který vykonává vykonávající model by měl reprodukovat vykonávání chování určené pro něj (pro co?) by the base semantics. Uááágggrhhh.
Behavioral Semantics – mapování odpovídajícího jazykového elementu pro specifikaci dynamického chování vyúsťujícího do změn v čase na instance v sémantice domény, ve které je jazyk použit.
Compact Subset – pro potřeby standardu fUML se jedná o malou podmnožinu konceptu UML pro dosažení výpočetní úplnosti (no ty kráso).
Computationally Complete – výpočetně úplná podmnožina UML, která dokáže uspokojivě vyjádřit definici modelů, které mohou být automaticky spuštěné na počítači nebo ve vykonávajícím nástroji (execution tool, viz dále).
Execution Model – model, který poskytuje kompletní, abstraktní specifikaci, kterou musí splňovat vykonávající nástroj.
Execution Semantics – chovací sémantika konstruktů UML, které specifikují provozuschopné akce v čase, popisující či omezující schopnosti chování v modelované doméně.
Execution Tool – libovolný nástroj, který je schopen spouštěn validní UML model založený na fUML.
Foundation Subset – podmnožina UML, které je přiřazena sémantika spustitelnosti.
Static Semantics – potenciální, kontextově závislé omezení, které příkaz jazyka musí splňovat, aby byl well-formed.
Structural Semantics – mapování odpovídajícího jazykového elementu na instance v sémantice modelu, ve kterém je v daném jazyce zaznamenán nějaký příkaz.
Syntax – pravidla, jak tvořit správně formulované příkazy v jazyce (jakém?) nebo pro validaci toho, že navržený příkaz je opravdu správně.
Overview of abstract syntax
fUML je mezičlánek mezi „surface subset“ of UML (co to sakra je?) používané pro modelování a cílovým jazykem používaným pro běh modelu.
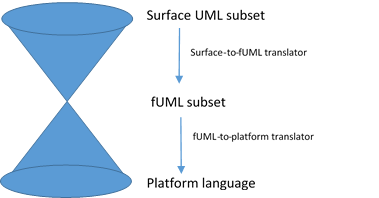
To tedy vyžaduje schopnost překladu ze surface subset UML (sakra, pořád nevím, co to je) do fUML a z fUML do cílové platformy.
V tomto kontextu (sakra, co to je surface subset UML? Povrchní podmnožina UML? Povrchové množení UML?) je fUML určeno třemi kritérii:
- Kompaktnost – podmnožina by měla být malá kvůli ulehčení definice jasné sémantiky a implementace běhových nástrojů.
- Jednoduchost překladu – podmnožina by měla umožnit přímý překlad z common surface subsets of UML (grrrrrrrrrrrrrr) do fUML a z fUML do jazyka cílové platformy.
- Funkčnost akcí – fUML pouze specifikuje, jak vykonávat UML akce. fUML tedy neobsahuje funkcionalitu vyžadující sjednocenou množinu UML akcí.
Mám to sakra chápat tak, že fUML je ve skutečnosti jen předpis pro to, jak si udělat vlastní executable UML? Něco mezi úrovní M3 a M2?
Předchozí tři body přinášení komplikace. Pokud např. máme surface vlastnost UML VlastnostX, tak bychom měli mít stejnou vlastnost i v jazyce platformy (např. v Javě). Jenže ji nemusíme mít v fUML. V takovém případě překlad do fUML musí použít jiné možnosti fUML. A překlad do jazyka platformy takovou „jinou“ možnost musí rozeznat a správně ji použít. Kompaktnost je pak v kolizi s jednoduchostí překladu.
Na druhou stranu, pokud by fUML VlastnostX uměla, narůstá komplexita. To nemusí být v jednom případě na škodu, ovšem postupem času může docházet k nabalování. A to není žádoucí.
fUML se snaží vyřešit vhodnou vyváženost mezi kompaktností a jednoduchostí překladu. Nemá např. výchozí hodnoty atributů, má ale třídy a operace. Stejně tak má komentáře či možnost dělení modelu do balíků.
Overview of Execution Model
Execution model je sám o sobě modelem napsaným v fUML, který určuje, jak jsou fUML modely vykonávány. Tato cykličnost je narušena oddělením specifikace základní sémantiky od podmnožiny fUML používané ve vykonávajícím modelu.
Behavioral Semantics
Vykonávaný model je formální a provozuschopná specifikace vykonávající sémantiky fUML. Tedy, že definuje procedury pro požadované změny, které se dějí při vykonávání modelu. Je to opak k deklarativnímu přístupu.
Vykonávaný model je sám o sobě spustitelný, objektově orientovaný model fUML of a fUML execution engine (uff). Aby bylo možné plně specifikovat chovací sémantiku fUML, vykonávaný model musí plně definovat své vlastní chování, tedy musí plně specifikovat každou metodu operace a chování klasifikátoru. Jelikož jediný typ chování, který fUML podporuje, je aktivita, každé chování musí být modelované pomocí aktivit.
Alf (6 %)
Zkoušené oblasti:
- Scope
- Semantic Conformance
- Integration with UML Models
- Lexical Structure
Zdroje:
- [ALF] Action Language for Foundational UML (Alf)
- 1 Scope: All
- 2.3 Semantic Conformance: All
- 6.1 Overview – General: All
- 6.2 Integration with UML Models: All
- 6.4 Lexical Structure: All
Scope
Alf (Action Language for Foundational UML) je textová, do hloubky nejdoucí reprezentace (textual surface representation, opět ono surface…) pro elementy modelované v UML. Sémantika vykonávání Alfu je dána mapováním syntaxe Alfu na abstraktní syntaxi fUML. Výsledek běhu Alfu je tedy dán sémantikou fUML modelu, na který je Alf mapován.
Primárním cílem jazyka akcí je možnost používat textový zápis, je-li třeba jej upřednostnit před grafickou notací. Přesto Alf poskytuje i rozšířenou notaci, která může být použita pro reprezentování strukturálních elementů. To znamená, že UML model může být celý reprezentován v Alfu.
Klíčové vlastnosti Alfu:
- Podobný jazyku C (C-legacy).
- Ačkoliv používáte Alf, není třeba kvůli tomu měnit model (např. názvy elementů z češtiny do cestinybezmezer).
- Podporuje jmenné prostory.
- Používá implicitní typový systém (není třeba tedy nic explicitně deklarovat).
- Alf má schopnost OCL pro manipulaci se sekvencemi hodnot.
Semantic Conformance
Sémantika vykonávání Alfu je popsána ve standardu jednak neformálně a jednak je specifikována formálně mapováním na fUML. Odpovídající nástroj poté musí implementovat sémantiku danou vybranou podmnožinou Alfu (jsou tři – minimum conformance, full conformance a extended conformance).
Takový nástroj má tři cesty k implementaci:
- Interpretace – text je interpretován podobně jako skript
- Kompilace – Alf je překompilován do fUML a běh je poté veden nad fUML modelem.
- Překladový běh – modelovací nástroj překládá Alf a UML model tak, jak je mu bližší do nějaké běhové podoby NEZALOŽENÉ na UML (např. exe file).
Bez ohledu na způsob implementace je nutné, aby všechny tři způsoby měly stejný výsledek z pohledu uživatele.
Integration wih UML Models
Zdrojový text zapsaný v Alfu může být jak v modelu, pro který je vytvořen, tak v jiném takovém modelu.
UML jako takové je definováno grafickou a textovou notací. Alf může být použit jako alternativa k uvedenému. Alf může být použit v těchto třech situacích:
- Kdekoliv je třeba vyjádřit hodnotu (value specification) – toho je možné dosáhnout jako body OpaqueExpression nebo může být Alf zápis přeložen do odpovídající UML aktivity
- Kdekoliv jsou použity příkazy:
- Definování chování UML akcí v aktivitě nebo interakcích. Opět, Alf lze použít v body OpaqueAction nebo přeložen do odpovídajícího strukturovaného uzlu (structured aktivity node).
- Definování celého chování – opět, jako body v OpaqueBehavior nebo jako překompilát do odpovídající aktivity.
- Reprezentování klasifikátorů a balíků, které jsou zamýšleny pro individuální referencování pomocí názvu.
Bez ohledu na překlady je fajn, když je zachován původní Alf text. Ten může být v původním modelu, ve speciálním modelu nebo jako textová poznámka napojená na nejvyšší prvek, který z překladu vzešel. Tato poznámka pak má stereotyp TextualRepresentation a tagovou hodnotu language s hodnotou Alf.
Lexical Structure
Lexikální struktura Alfu definuje rozdělení řetězců zdrojové podoby do tří typů vstupních prvků: bílé znaky (whitespace), komentáře a tokeny.
Lexikální analýza je proces konverze textu zapsaného v Alfu do odpovídajícího streamu vstupních elementů. Během této analýzy jsou komentáře a bílé znaky zahozeny.
Lexikální struktura je určena lexikální gramatikou, ve které jsou znaky terminálem a vstupní elementy vzniklé při lexikální analýze jdou neterminální (nebudu to více vysvětlovat, je třeba si vzpomenout na přednášku Základy překladačů na MFF UK). Lexikální gramatika je definována rozšířenou Backus-Naur formou (EBNF), jejíž konvenci lze vidět zde:
- Terminal element: „terminal“
- Non-terminal element: NonterminalElement
- Sequential element: Element1 Element2
- Alternative elements: Element1 | Element2
- Optional element (zero or one): [ Element ]
- Repeated element (zero or more): { Element }
- Production definition: NonterminalElement = …
Uložit
Uložit
Uložit
Uložit
Uložit
Uložit
Uložit
Uložit
Uložit
 Konečně nastala vhodná doba k tomu, abych mohl představit učebnici UML a OCUP 2 aneb Jak si certifikovat znalosti UML 2 pro přípravu k aktualizované úrovni OCUP 2 Intermediate. Po dlouhých týdnech psaní a revidování máte možnost mít 142 stran textu a diagramů, které budete určitě ke zkoušce potřebovat.
Konečně nastala vhodná doba k tomu, abych mohl představit učebnici UML a OCUP 2 aneb Jak si certifikovat znalosti UML 2 pro přípravu k aktualizované úrovni OCUP 2 Intermediate. Po dlouhých týdnech psaní a revidování máte možnost mít 142 stran textu a diagramů, které budete určitě ke zkoušce potřebovat. Text učebnice konečně dospěl do stádia, kdy jej lze nabídnout vám všem. Jedná se o výrazně přepracované znění přípravy k předchozí verzi zkoušek dostupné na
Text učebnice konečně dospěl do stádia, kdy jej lze nabídnout vám všem. Jedná se o výrazně přepracované znění přípravy k předchozí verzi zkoušek dostupné na 






